굉장히 빠르게 정규분포 난수 생성하기
들어가기에 앞서
정규분포 난수 생성은 널리 사용되며, 특히 통계학과 데이터 과학에서 중요한 역할을 한다.
가볍게 쓰기에는 파이썬이나 C++에서 제공하는 함수를 쓰면 된다.
그런데, 레이더 시뮬레이션 처럼 대량의 난수를 생성해야 할 때는 속도가 중요하다.
이 경우에는 표준 라이브러리를 사용하는 것은 느릴 수 있다.
수백만 개의 샘플을 생성해야 할 경우 눈에 띄는 차이를 가져온다.
따라서, 더 효율적인 방법을 고려해보아야 한다.
C++로 정규분포 난수 생성
C++11 이상에서는 <random> 헤더를 사용하여 정규분포 난수를 생성할 수 있다.
MT19937와 함께 사용하면 고품질의 난수를 효율적으로 생성할 수 있다.
#include <iostream>
#include <random>
int main() {
std::random_device rd;
std::mt19937 gen(rd());
std::normal_distribution<float> dist(0.0f, 1.0f);
constexpr int num_samples = 1024;
for (int i = 0; i < num_samples; ++i)
std::cout << dist(gen) << std::endl;
return 0;
}
Intel IPP로 정규분포 난수 생성
Intel Integrated Performance Primitives (IPP)는 고성능의 수학 루틴을 제공한다.
이 중에는 정규분포 난수를 생성하는 함수도 있다.
C++11의 random 보다 조금은 더 빠른 생성이 가능하다.
#include <iostream>
#include <random>
#include <ipp.h>
int main() {
std::random_device rd;
const unsigned int seed = (unsigned int)rd();
constexpr int num_samples = 1024;
Ipp64f* samples = ippsMalloc_64f(num_samples);
IppsRandGaussState_64f* pRand;
int sizeRndObj;
ippsRandGaussGetSize_64f(&sizeRndObj);
pRand = (IppsRandGaussState_64f*)ippsMalloc_8u(sizeRndObj);
ippsRandGaussInit_64f(pRand, 0.0f, 1.0f, seed);
ippsRandGauss_64f(samples, num_samples, pRand);
for (int i = 0; i < num_samples; ++i)
std::cout << samples[i] << std::endl;
ippsFree(samples);
ippsFree(pRand);
return 0;
}
이게 최선입니까? 확실해요?
위의 방법들이면 상당히 좋은 품질의 정규분포 난수를 꽤 쉽게 생성할 수 있다.
그러나, 생성할 난수의 양이 많아지면 속도가 중요해진다.
예컨데, 5억개를 생성하려고 한다면, 속도가 더 큰 고려 사항이 된다.
더불어, float로 생성하는가 double로 생성하는가 중요한 요소가 될 수 있다.
정규분포 난수를 고속으로 생성하는 알고리즘이 몇 가지가 있다.
그 중에서도 Ziggurat, Box-Muller 등이 많이 사용된다.
이러한 알고리즘들은 높은 속도를 유지하면서도, 높은 품질의 난수를 생성하는 데에 도움을 준다.
따라서, 대량의 난수를 필요로 하는 응용 프로그램에서는 이러한 알고리즘을 고려해보는 것이 좋다.
Box-Muller 알고리즘
Box-Muller 알고리즘은 가장 널리 사용되는 정규분포 난수 생성 알고리즘 중 하나이다.
이 알고리즘의 아이디어는 극좌표를 직교좌표로 변환하는 것이다.
정교한 증명은 쉽지 않지만, 정리된 내용은 기적적으로 단순하다.
균등분포 난수 \(u \left(0,1\right], v \left[0,1\right]\)를 생성하고, 다음과 같이 변환한다.
(여기서 u가 0이 될 수 없는 것은 \(\ln u\)가 발산하기 때문)
\(\begin{align} x = \sqrt{-2\ln u} \cos\left(2\pi v\right) \end{align}\)
\(\begin{align} y = \sqrt{-2\ln u} \sin\left(2\pi v\right) \end{align}\)
이렇게 생성된 \(x\)와 \(y\)는 서로 독립이고, 표준 정규분포 \(\begin{align} \mathcal{N} \left(0, 1 \right) \end{align}\)를 따른다.
C++로 Box-Muller 알고리즘 구현
기본적인 틀은 위의 코드와 동일하다.
seed는 random_device로 생성하고, 난수 생성은 MT19937을 사용한다.
#include <iostream>
#include <random>
#include <cmath>
int main() {
std::random_device rd;
std::mt19937 gen(rd());
std::uniform_real_distribution<float> dist(0.0f, 1.0f);
constexpr float twopif = float(2.0 * 3.14159265358979323846);
constexpr int num_samples = 1024;
for (int i = 0; i < num_samples; i += 2) {
const float u = 1.0f - dist(gen); // [0, 1) -> (0, 1]
const float v = dist(gen);
const float radius = std::sqrt(-2.0f * std::log(u));
const float x = radius * std::cos(twopif * v);
const float y = radius * std::sin(twopif * v);
std::cout << x << ", " << y << std::endl;
}
return 0;
}
IPP로 Box-Muller 알고리즘 구현
IPP의 내장 함수를 사용하지 않고, 직접 Box-Muller 알고리즘을 구현할 수도 있다.
이 때, 난수의 생성 자체부터 직접 구현하면 좀 더 빠른 성능을 기대할 수 있다.
#include <iostream>
#include <random>
#include "ipp.h"
int main() {
constexpr float twopif = float(2.0 * 3.14159265358979323846);
std::random_device rd;
unsigned int seed = (unsigned int)rd();
constexpr int num_samples = 512;
Ipp32f* buf = ippsMalloc_32f(num_samples * 6);
Ipp32f* u1 = buf;
Ipp32f* u2 = buf + num_samples;
Ipp32f* t0 = buf + num_samples * 2;
Ipp32f* t1 = buf + num_samples * 3;
Ipp32f* r0 = buf + num_samples * 4;
Ipp32f* r1 = buf + num_samples * 5;
for (int i = 0; i < num_samples; ++i)
{
// Numerical Recipes ranqd1, Chapter 7.1
seed = seed * 1664525 + 1013904223;
union {
unsigned int u;
float f;
} u;
u.u = (seed >> 9) | 0x3F800000;
t0[i] = u.f - 1.0f;
seed = seed * 1664525 + 1013904223;
u.u = (seed >> 9) | 0x3F800000;
u2[i] = u.f - 1.0f;
}
ippsSubCRev_32f(t0, 1.0f, u1, num_samples); // [0, 1) -> (0, 1]
ippsLn_32f_A11(u1, t0, num_samples);
ippsMulC_32f(t0, -2.0f, u1, num_samples);
ippsSqrt_32f_A11(u1, t0, num_samples); // t0: radius
ippsMulC_32f(u2, twopif, u1, num_samples); // u0: theta
ippsCos_32f_A11(u1, u2, num_samples); // u1: cos(theta)
ippsSin_32f_A11(u1, t1, num_samples); // t1: sin(theta)
ippsMul_32f(t0, u2, r0, num_samples); // r0: radius * cos(theta)
ippsMul_32f(t0, t1, r1, num_samples); // r1: radius * sin(theta)
for (int i = 0; i < num_samples; ++i)
std::cout << r0[i] << ", " << r1[i] << std::endl;
ippsFree(buf);
}
AVX를 극단적으로 활용하는 방법
위에 언급된 다양한 방법들이 있고, 여기 언급되지 않은 방법들도 있다.
그런데, sse_mathfun.h와 같은 초고속 근사 라이브러리를 사용하는 방법이 있다.
이 라이브러리는 SSE2 등을 활용하여 삼각함수, 지수함수 등을 빠르게 계산할 수 있게 해준다.
또한, AVX2를 활용한 수정 버전도 쉽게 찾을 수 있고, 이를 이용해 AVX-512 버전도 만들었다.
이러한 방법들은 대량의 난수를 생성하는 데 있어 성능을 극대화할 수 있다.
#include <iostream>
#include <random>
#include <cmath>
#include <immintrin.h>
#include "avx_mathfun.h"
int main() {
std::random_device rd;
constexpr float twopif = float(2.0 * 3.14159265358979323846);
// Numerical Recipes ranqd1, Chapter 7.1, x = x * 1664525 + 1013904223
_PS256_CONST_TYPE(lcg_a, uint32_t, 1664525);
_PS256_CONST_TYPE(lcg_b, uint32_t, 1013904223);
_PS256_CONST_TYPE(lcg_mask, uint32_t, 0x3F800000);
_PS256_CONST(twopi, twopif);
_PS256_CONST(one, 1.0f);
_PS256_CONST(minustwo, -2.0f);
unsigned int seed = (unsigned int)rd();
__m256i x0 = _mm256_setr_epi32(seed, seed+1, seed+2, seed+3, seed+4, seed+5, seed+6, seed+7);
__declspec(align(32)) float data[16];
constexpr int num_samples = 1024;
for (int i = 0; i < num_samples; i += 16) {
x0 = _mm256_add_epi32(_mm256_mullo_epi32(x0, *(__m256i*)_ps256_lcg_a), *(__m256i*)_ps256_lcg_b);
__m256i x1 = _mm256_or_si256(_mm256_srli_epi32(x0, 9), *(__m256i*)_ps256_lcg_mask);
__m256 u1 = _mm256_sub_ps(_mm256_castsi256_ps(x1), *(__m256*)_ps256_1);
x0 = _mm256_add_epi32(_mm256_mullo_epi32(x0, *(__m256i*)_ps256_lcg_a), *(__m256i*)_ps256_lcg_b);
x1 = _mm256_or_si256(_mm256_srli_epi32(x0, 9), *(__m256i*)_ps256_lcg_mask);
__m256 u2 = _mm256_sub_ps(_mm256_castsi256_ps(x1), *(__m256*)_ps256_1);
u1 = _mm256_sub_ps(_mm256_set1_ps(1.0f), u1); // [0, 1) -> (0, 1]
const __m256 radius = _mm256_sqrt_ps(_mm256_mul_ps(*(v8sf*)_ps256_minustwo, log256_ps(u1)));
__m256 theta = _mm256_mul_ps(*(v8sf*)_ps256_twopi, u2);
__m256 sintheta, costheta;
sincos256_ps(theta, &sintheta, &costheta);
_mm256_store_ps(&data[0], _mm256_mul_ps(radius, costheta));
_mm256_store_ps(&data[8], _mm256_mul_ps(radius, sintheta));
for (int j = 0; j < 16; ++j)
std::cout << data[j] << ", ";
std::cout << std::endl;
}
return 0;
}
생성된 난수들은 정규분포를 잘 따르는가?
위에 적힌 코드 외에 다양한 구현을 시험했었다.
Box-Muller 알고리즘을 IPP로 구현하는 방식의 경우 몇 가지 아이디어를 낼 수 있었다.
1억 개의 float 난수를 생성했다.
이에 대해 평균, 표준편차 외에 왜도(skewness), 첨도(kurtosis) 도 계산했다.
| 구분 | mean | stddev | minimum | maximum | skewness | kurtosis |
|---|---|---|---|---|---|---|
| cpp11random | -0.000005 | 0.999915 | -5.952203 | 5.852517 | -0.000359 | 0.000154 |
| ipps_normalrand | 0.000047 | 1.000019 | -5.536599 | 5.401316 | 0.000060 | -0.000151 |
| boxmuller | -0.000197 | 0.999958 | -5.384234 | 5.521977 | 0.000174 | -0.000540 |
| boxmuller_ipps1 | -0.000043 | 1.000009 | -5.614546 | 5.423891 | -0.000027 | 0.000619 |
| boxmuller_ipps2 | 0.000064 | 0.999979 | -5.339377 | 5.516344 | -0.000118 | -0.000513 |
| boxmuller_ipps3 | 0.000174 | 0.999995 | -5.926759 | 5.476528 | -0.000041 | 0.000476 |
| boxmuller_sse2 | -0.000184 | 1.000055 | -5.447542 | 5.603260 | -0.000079 | 0.000671 |
| boxmuller_avx | -0.000229 | 0.999932 | -5.448394 | 5.351513 | -0.000472 | 0.000241 |
| boxmuller_avx512 | 0.000009 | 1.000098 | -5.446379 | 5.486234 | 0.000117 | -0.000745 |
모든 알고리즘에서 평균, 왜도, 첨도 모두 0.01 미만이며, 표준편차 역시 1에 가까운 값을 보였다.
한편, 동작 시간은 아래와 같았다.
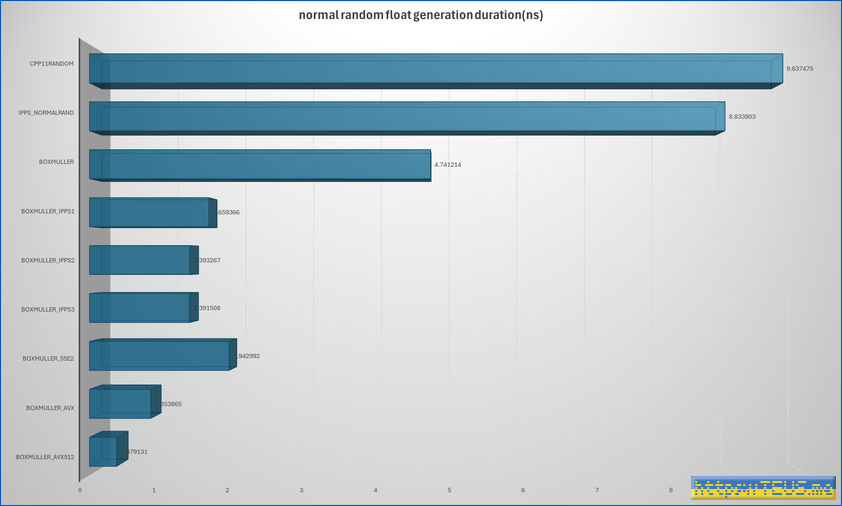
위의 그래프에서 볼 수 있듯이, C++11의 random을 사용한 경우가 가장 느리고, AVX-512를 사용한 경우가 가장 빨랐다.
동작 속도의 차이는 무려 25배 이상이었다. (Ryzen 9700X 만세)
단, AVX-512는 인텔 CPU에서는 사실상 사용이 불가능하므로 AVX2를 사용해야 한다.
이 때는 11배 이상의 속도 차이가 있었다.
1억 개의 double 난수에 대해 같은 작업을 수행했을 때, 결과는 아래와 같았다.
| 구분 | mean | stddev | minimum | maximum | skewness | kurtosis |
|---|---|---|---|---|---|---|
| cpp11random | -0.000016 | 0.999961 | -5.824899 | 5.594587 | 0.000065 | -0.000451 |
| ipps_normalrand | -0.000112 | 0.999988 | -5.807647 | 5.776418 | -0.000029 | -0.000211 |
| boxmuller | -0.000062 | 1.000011 | -5.387832 | 6.044310 | 0.000007 | 0.000277 |
| boxmuller_ipps1 | 0.000023 | 1.000008 | -5.213457 | 5.271897 | -0.000237 | 0.000489 |
| boxmuller_ipps2 | -0.000012 | 0.999968 | -5.219423 | 5.222828 | 0.000613 | -0.000015 |
| boxmuller_ipps3 | 0.000032 | 0.999953 | -5.926759 | 5.476528 | 0.000008 | 0.001325 |
역시 평균, 왜도, 첨도 모두 0.01 미만이었으며, 표준편차는 1에 가까웠다.
동작 시간은 아래와 같았다.
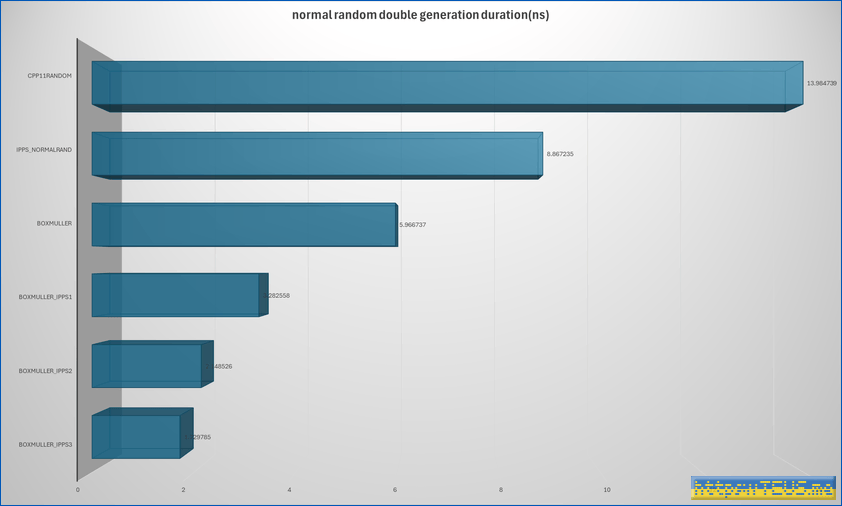
double에서는 AVX를 활용한 구현은 적용하지 않았다.
C++11의 random을 사용한 경우가 가장 느리고, Box-Muller를 IPP로 구현한 것이 가장 빨랐다.
동작 속도의 차이는 8배 이상이었다.
결론
정규분포 난수를 생성하는 방법은 다양하다.
위에 명칭만 언급된 Ziggurat 외에도, CLT(central limit theorem), Marsaglia polar method 도 있다.
다양한 테스트를 수행한 결과, Box-Muller 알고리즘을 AVX-512로 float에서 구현한 것이 가장 빨랐다.
물론, 이 경우 인텔 CPU에서는 사실상 적용이 불가능하다는 단점이 있고, AVX2 구현을 사용해야 한다.
또한 AVX2를 활용하는 경우에도 성능 이점을 기대할 수 있다.
하나의 함수만으로 처리해야 한다면, AVX2와 AVX-512 버전을 모두 구현해서 CPU에 따라 선택하는 것이 좋다.
이 정도의 작업을 대규모로 수행한다면 SSE2 이하의 CPU는 사용하지 않는 것이 합리적이다.
단, SIMD 개발에 익숙하지 않다면, IPP를 사용하는 것이 가장 좋은 선택이 될 수 있다.
코드의 가독성과 유지보수성까지 고려하면 IPP의 장점도 상당하기 때문이다.
참고 자료
