오랜만에 상용 조합형 한글을 변환해보았다
요즘에도 상용 조합형 한글을 볼 일이 있다고?
요즘은 상용 조합형으로 인코딩된 텍스트 파일을 볼 일은 없다.
조합형 한글의 아름다움을 지켜야 한다고 외쳤던 얘기들도 이미 20세기의 옛날 얘기일 뿐이다.
그런데, 예전 《월간 마이크로 소프트웨어》 관련 자료들을 뒤지다가 재미있는 자료를 발견했다.
무려 마이크로소프트웨어CD ISSUE 1,2,3 (1988~1995)를 발견한 것이다.
한 귀인께서 구글 드라이브에서 ISO 파일을 직접 받을 수 있는 링크를 올려주셨다.
이 CD 자료들에는 옛날 자료답게 상용 조합형으로 인코딩된 파일들이 많이 들어있다.
그리고 이 파일들을 Notepad4로 열어보면 아래와 같이 깨져서 나온다.
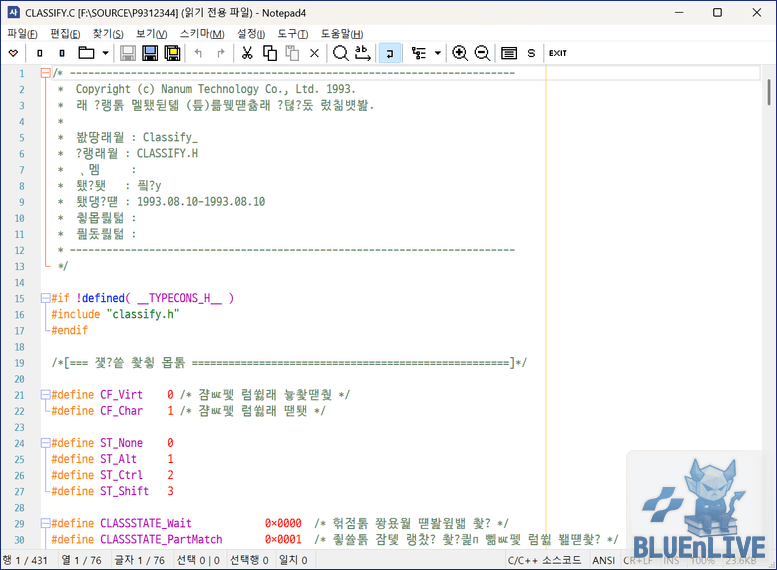
물론, 우리의 Notepad4에는 이 경우를 위한 기능이 이미 마련되어 있다.
인코딩 새로 읽기에서 조합을 선택하면 간단히 해결된다.
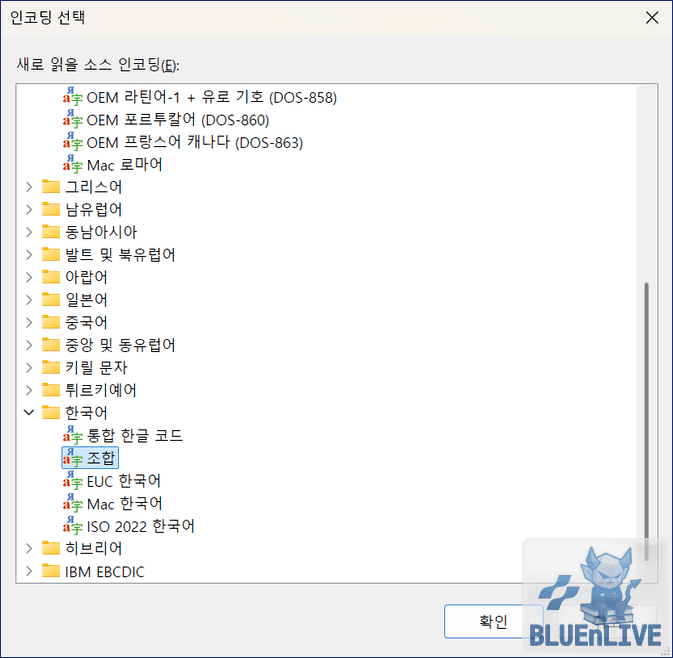
아래와 같이 정상적으로 읽히는 모습을 쉽게 볼 수 있다.
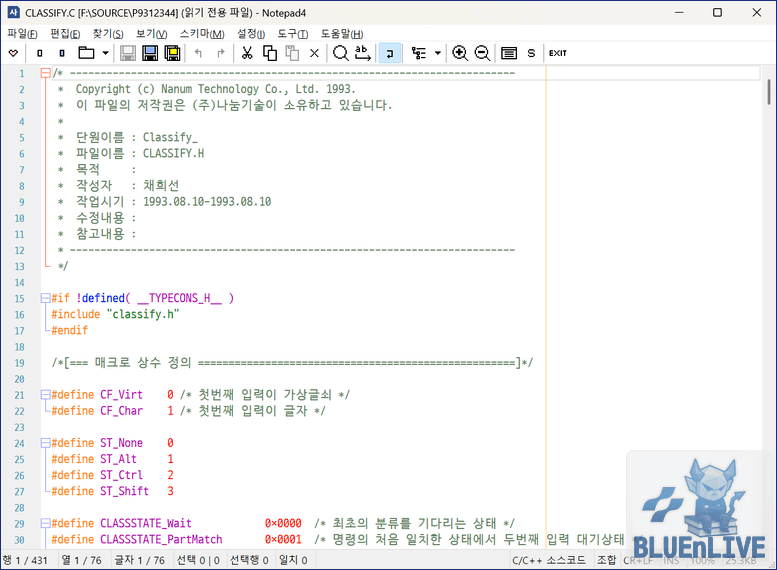
하지만, Notepad++에서는 어떨까?
Notepad++는 Notepad4에 비해 다중 탭과 플러그인 기능으로 무장한 만능 도구이다.
하지만 이렇게 기능이 많지만 조합형 한글 텍스트를 처리하는 기능은 없다.
요즘 Notepad4에 적용했던 기능들을 Notepad++ 용으로 구현하는 플러그인을 개발하고 있다.
이 플러그인에 상용 조합형 한글을 처리하는 기능을 추가하기로 했다.
물론, Notepad4에서 읽은 뒤 복사해도 되지만, 작업량도 크지 않고, 추억에 빠지는 기분으로 구현.
구현
상용 조합형 한글의 구성은 MSB를 1로 두고 초성, 중성, 종성에 각각 5비트를 할당하는 구성이다.
| 코드 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 초성 | - | 채움 | ㄱ | ㄲ | ㄴ | ㄷ | ㄸ | ㄹ | ㅁ | ㅂ | ㅃ | ㅅ | ㅆ | ㅇ | ㅈ | ㅉ | ㅊ | ㅋ | ㅌ | ㅍ | ㅎ | - | - | - | - | - | - | - | - | - | - | - |
| 중성 | - | - | 채움 | ㅏ | ㅐ | ㅑ | ㅒ | ㅓ | - | - | ㅔ | ㅕ | ㅖ | ㅗ | ㅘ | ㅙ | - | - | ㅚ | ㅛ | ㅜ | ㅝ | ㅞ | ㅟ | - | - | ㅠ | ㅡ | ㅢ | ㅣ | - | - |
| 종성 | - | 채움 | ㄱ | ㄲ | ㄳ | ㄴ | ㄵ | ㄶ | ㄷ | ㄹ | ㄺ | ㄻ | ㄼ | ㄽ | ㄾ | ㄿ | ㅀ | ㅁ | - | ㅂ | ㅄ | ㅅ | ㅆ | ㅇ | ㅈ | ㅊ | ㅋ | ㅌ | ㅍ | ㅎ | - | - |
현재 유니코드의 한글 영역은 조합형으로 구성되어 있기 때문에 값만 잘 맞추면 변환은 간단하다.
하지만… 그 전에 고려해야 할 사항이 좀 있다.
- 이 변환은 KSSM to Unicode가 아니라 KSSM to UHC로 구현
- 이를 처리하기 위해
WideCharToMultiByte()함수를 활용함
- 이를 처리하기 위해
- 초성, 중성, 종성이 단독으로 나오는 경우는 단위 자모로 변환
- 초성, 종성만 나오거나 중성, 종성만 나오는 경우에는 각각의 단위 자모로 변환
이 점까지 고려해서 아래와 같이 변환 테이블을 만든다.
// 조합형 초성 값(2~20) -> [유니코드 음절 인덱스, 호환 자모 코드]
static const int chosung_table[32][2] = {
{ -1, 0x0000 }, { -1, 0x0000 }, // 0, 1 (1은 채움)
{ 0, 0x3131 }, { 1, 0x3132 }, { 2, 0x3134 }, // 2:ㄱ, 3:ㄲ, 4:ㄴ
{ 3, 0x3137 }, { 4, 0x3138 }, { 5, 0x3139 }, // 5:ㄷ, 6:ㄸ, 7:ㄹ
{ 6, 0x3141 }, { 7, 0x3142 }, { 8, 0x3143 }, // 8:ㅁ, 9:ㅂ, 10:ㅃ
{ 9, 0x3145 }, { 10, 0x3146 }, { 11, 0x3147 }, // 11:ㅅ, 12:ㅆ, 13:ㅇ
{ 12, 0x3148 }, { 13, 0x3149 }, { 14, 0x314A }, // 14:ㅈ, 15:ㅉ, 16:ㅊ
{ 15, 0x314B }, { 16, 0x314C }, { 17, 0x314D }, // 17:ㅋ, 18:ㅌ, 19:ㅍ
{ 18, 0x314E }, // 20:ㅎ
{ -1, 0x0000 }, { -1, 0x0000 }, { -1, 0x0000 }, { -1, 0x0000 }, // 21~24
{ -1, 0x0000 }, { -1, 0x0000 }, { -1, 0x0000 }, { -1, 0x0000 }, // 25~28
{ -1, 0x0000 }, { -1, 0x0000 }, { -1, 0x0000 } // 29~31
};
// 조합형 중성 값(3~26) -> [유니코드 음절 인덱스, 호환 자모 코드]
static const int jungsung_table[32][2] = {
{ -1, 0x0000 }, { -1, 0x0000 }, { -1, 0x0000 }, // 0, 1, 2 (2는 채움)
{ 0, 0x314F }, { 1, 0x3150 }, { 2, 0x3151 }, // 3:ㅏ, 4:ㅐ, 5:ㅑ
{ 3, 0x3152 }, { 4, 0x3153 }, // 6:ㅒ, 7:ㅓ
{ -1, 0x0000 }, { -1, 0x0000 }, // 8, 9 (빈 값)
{ 5, 0x3154 }, { 6, 0x3155 }, { 7, 0x3156 }, // 10:ㅔ, 11:ㅕ, 12:ㅖ
{ 8, 0x3157 }, { 9, 0x3158 }, { 10, 0x3159 }, // 13:ㅗ, 14:ㅘ, 15:ㅙ
{ -1, 0x0000 }, { -1, 0x0000 }, // 16, 17 (빈 값)
{ 11, 0x315A }, { 12, 0x315B }, { 13, 0x315C }, // 18:ㅚ, 19:ㅛ, 20:ㅜ
{ 14, 0x315D }, { 15, 0x315E }, { 16, 0x315F }, // 21:ㅝ, 22:ㅞ, 23:ㅟ
{ -1, 0x0000 }, { -1, 0x0000 }, // 24, 25 (빈 값)
{ 17, 0x3160 }, { 18, 0x3161 }, { 19, 0x3162 }, // 26:ㅠ, 27:ㅡ, 28:ㅢ
{ 20, 0x3163 }, // 29:ㅣ
{ -1, 0x0000 }, { -1, 0x0000 } // 30~31
};
// 조합형 종성 값(2~29) -> [유니코드 음절 인덱스, 호환 자모 코드]
static const int jongsung_table[32][2] = {
{ -1, 0x0000 }, // 0
{ 0, 0x0000 }, // 1 (채움)
{ 1, 0x3131 }, { 2, 0x3132 }, { 3, 0x3133 }, // 2:ㄱ, 3:ㄲ, 4:ㄳ
{ 4, 0x3134 }, { 5, 0x3135 }, { 6, 0x3136 }, // 5:ㄴ, 6:ㄵ, 7:ㄶ
{ 7, 0x3137 }, { 8, 0x3139 }, { 9, 0x313A }, // 8:ㄷ, 9:ㄹ, 10:ㄺ
{ 10, 0x313B }, { 11, 0x313C }, { 12, 0x313D }, // 11:ㄻ, 12:ㄼ, 13:ㄽ
{ 13, 0x313E }, { 14, 0x313F }, { 15, 0x3140 }, // 14:ㄾ, 15:ㄿ, 16:ㅀ
{ 16, 0x3141 }, // 17:ㅁ
{ -1, 0x0000 }, // 18 (빈 값)
{ 17, 0x3142 }, { 18, 0x3144 }, { 19, 0x3145 }, // 19:ㅂ, 20:ㅄ, 21:ㅅ
{ 20, 0x3146 }, { 21, 0x3147 }, { 22, 0x3148 }, // 22:ㅆ, 23:ㅇ, 24:ㅈ
{ 23, 0x314A }, { 24, 0x314B }, { 25, 0x314C }, // 25:ㅊ, 26:ㅋ, 27:ㅌ
{ 26, 0x314D }, { 27, 0x314E }, // 28:ㅍ, 29:ㅎ
{ -1, 0x0000 }, { -1, 0x0000 } // 30, 31
};
그리고, 이 표를 이용해서 변환하면 된다.
아래의 코드는 Notepad++에서 사용하기 위해 Scintilla를 사용한 구현이다.
코드 페이지는 무조건 949에서만 동작하도록 구현되어 있다.
Sci_Position totalLen = ::SendMessage(hSci, SCI_GETLENGTH, 0, 0);
std::vector<char> src(totalLen + 1);
::SendMessage(hSci, SCI_GETTEXT, totalLen + 1, (LPARAM)src.data());
std::vector<wchar_t> wResult;
wResult.reserve(static_cast<size_t>(totalLen * 1.5));
const unsigned char* pSrc = reinterpret_cast<const unsigned char*>(src.data());
for (Sci_Position i = 0; i < totalLen; ) {
unsigned char b1 = pSrc[i];
size_t prevWSize = wResult.size();
if (!(b1 & 0x80)) { // ASCII
wResult.push_back(static_cast<wchar_t>(b1));
i++;
}
else if (i + 1 < totalLen) { // KSSM (Johab)
unsigned char b2 = pSrc[i + 1];
// 추억의 비트 구조: 1 CCCCC JJ | JJJ TTTTT
int cho = (b1 >> 2) & 0x1F;
int jung = ((b1 & 0x03) << 3) | (b2 >> 5);
int jong = b2 & 0x1F;
bool converted = false;
if (cho >= 2 && cho <= 20 && jung >= 3 && jung <= 29) {
int cIdx = chosung_table[cho][0];
int mIdx = jungsung_table[jung][0];
int tIdx = (jong >= 1 && jong <= 29) ? jongsung_table[jong][0] : 0;
if (cIdx != -1 && mIdx != -1) {
wResult.push_back(static_cast<wchar_t>(0xAC00 + (cIdx * 588) + (mIdx * 28) + (tIdx > 0 ? tIdx : 0)));
converted = true;
}
}
if (!converted) {
// 조합 실패 시 호환 자모 보존
if (cho < 32 && chosung_table[cho][1] != 0) wResult.push_back(static_cast<wchar_t>(chosung_table[cho][1]));
if (jung < 32 && jungsung_table[jung][1] != 0) wResult.push_back(static_cast<wchar_t>(jungsung_table[jung][1]));
if (jong < 32 && jongsung_table[jong][1] != 0) wResult.push_back(static_cast<wchar_t>(jongsung_table[jong][1]));
}
i += 2;
}
else { i++; }
}
// [4] 결과 적용
if (!wResult.empty()) {
int ansiLen = WideCharToMultiByte(949, 0, wResult.data(), (int)wResult.size(), nullptr, 0, nullptr, nullptr);
std::vector<char> ansiResult(ansiLen + 1, 0);
WideCharToMultiByte(949, 0, wResult.data(), (int)wResult.size(), ansiResult.data(), ansiLen, nullptr, nullptr);
// ansiResult에 변환된 결과가 저장돼있음
// 결과를 활용하는 코드를 여기 기술
}
그외 사항
실제 Notepad++의 플러그인에는 선택영역을 계산하는 코드 및 읽기 전용 파일에 대한 코드 등이 추가로 구현돼있다.
- 자모로 변환하는 과정에서 문자열의 길이가 변하는 경우에도 동일한 선택 영역을 유지해야 함
- 읽기 전용 파일은 수정이 불가능해야 하나, 이 경우는 다시 읽는 개념에 가까워 변환하도록 작성함
