2025 MSU 하드웨어 비디오 코덱 평가 간단한 분석
개요: 규격을 압도하는 구현 - 2025 MSU 하드웨어 비디오 코덱 평가 간단한 분석
모스크바 국립대(MSU)에서 얼마 전 공개한 Hardware Video Codecs Comparison 2025를 읽었다.
미디어 고관심층 입장에서 여러모로 시사하는 바가 크다.
흔히 코덱을 이야기할 때 세대론적 프레임에 갇히기 쉽다.
‘H.264보다 HEVC가 좋고, AV1이나 VVC는 무조건 우월하다’는 식이다.
기본적으로는, 적어도 스펙에 따르면 맞는 얘기다.
하지만 실제 실리콘 칩으로 구현하는 영역은 결과가 꽤 다르다.
위 주소에서는 간략 버전의 보고서는 무료로 다운이 가능하고, 상세 버전도 구매할 수 있다.
본 블로그의 분석 기준은 ‘crowd_run’ 시퀀스 하나로 잡았다.
화질 메트릭은 인간의 시각 인지 품질을 가장 잘 반영하는 ‘Y-VMAF’ 데이터다.
다른 영상과 지표도 경향성은 대동소이하다.
이 기준만으로도 하드웨어 코덱의 본질을 들여다보기에 충분하다.
1. 혼돈의 전장: RD 커브 전체 데이터
처음 전체 데이터를 마주하면 그야말로 혼돈이다.
시장의 구형 GPU부터 최신 데이터센터용 전용 칩까지 한데 뒤섞여 있다.
직관적인 트렌드를 읽어내기가 어렵다.
그냥 이 정도로 테스트를 많이 했다는 점만 보고 넘어간다.
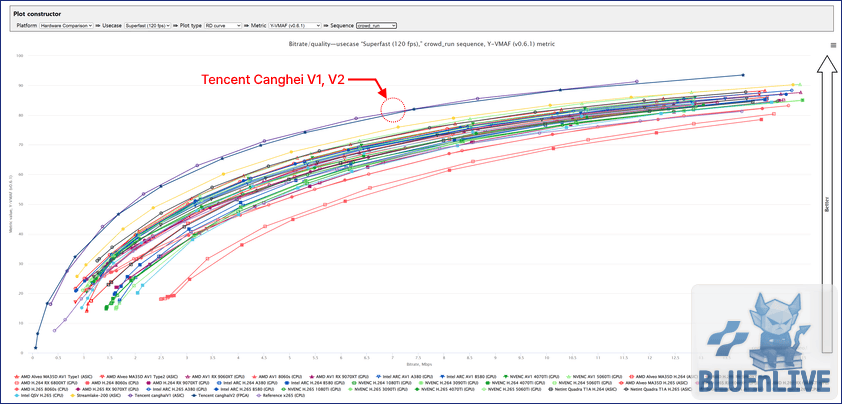 RD 커브 전체
RD 커브 전체
2. 첫 번째 필터링: 구형 하드웨어의 퇴장
의미 있는 분석을 위해 세대교체가 끝난 구형 GPU 라인업을 제외했다.
노이즈가 걷히기 시작한다.
현재 시장을 주도하는 주역들의 윤곽이 드러난다.
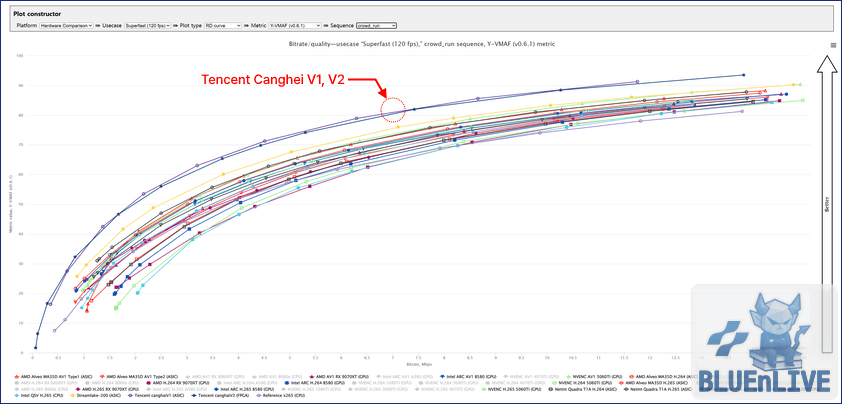 RD 커브 전체 중 구형 GPU 제외
RD 커브 전체 중 구형 GPU 제외
3. 압축 효율에 모든 것을 올인한 전용 칩의 세계
일단 GPU를 숨기고 데이터센터 전용 ASIC과 FPGA 장비만 정렬한 결과다.
이를 먼저 보여주는 이유는 전용 ASIC 칩에서 이 그래프 전체의 승자가 있기 때문이다.
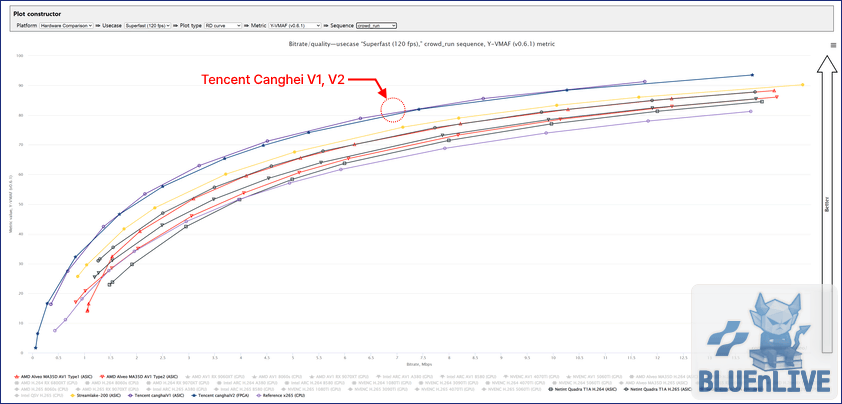 RD 커브에서 ASIC만 남김 (FPGA 포함)
RD 커브에서 ASIC만 남김 (FPGA 포함)
Tencent Canghai V1/V2, Kuaishou Streamlake-200이 상단을 독점한다.
이 칩들은 오직 비디오 압축 효율 극대화에만 엄청난 자본을 올인했다.
대용량 버퍼와 정밀한 모션 탐색 로직을 실리콘 다이에 아낌없이 박아 넣은 결과인 듯.
빅테크가 이토록 독하게 칩을 깎는 이유는 망 비용(Bandwidth Cost) 때문이다.
대규모 스트리밍 서비스에서는 비트레이트를 1%만 줄여도 매달 수억 원의 회선 비용이 절감된다.
게다가 시청자 환경에서 호환성이 가장 좋은 코덱은 여전히 HEVC다.
무지막지한 하드웨어 피지컬으로 HEVC의 압축률을 한계까지 짜내겠다는 집념의 결과물이다.
또 하나 눈에 띄는 점은 이 그래프에서 VVC 코덱은 오로지 Tencent Canghai V2 하나 뿐이다.
이 코덱이 가장 상단에 있긴 하지만, HEVC를 구현한 Tencent Canghai V1과 큰 차이가 없다.
4. 기준점 설정과 GPU의 진화: H.264
이 거대한 클라우드 거인들과 상용 GPU(NVIDIA, Intel, AMD)의 체급 차이를 코덱별로 대조해 본다.
여기서부터는 품질 극강을 보여주는 Tencent Canghai 2종과 S/W 인코더인 x265를 기준으로 두고 GPU를 비교한다.
첫 번째는 가장 오래된 H.264 규격이다.
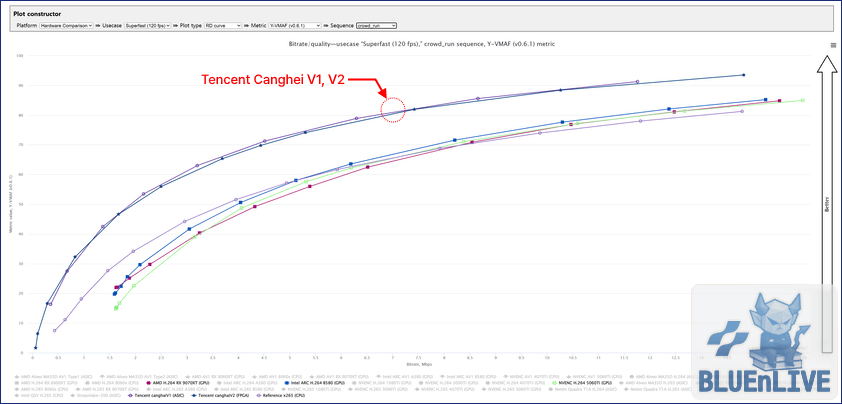 최신 GPU 3사의 H.264 vs Tencent ASIC / x265
최신 GPU 3사의 H.264 vs Tencent ASIC / x265
최신 GPU라도 H.264 규격 자체의 한계가 명확하다.
인코딩 속도를 위한 설계 특성 탓인지 상단의 Canghai ASIC 인코더와는 상당한 품질 격차가 존재한다.
심지어 x265 소프트웨어보다도 대체로 밀리는 결과를 보여준다.
5. 주류의 포지션: HEVC (H.265)
현재 가장 널리 쓰이는 주류 코덱인 HEVC 환경에서의 비교다.
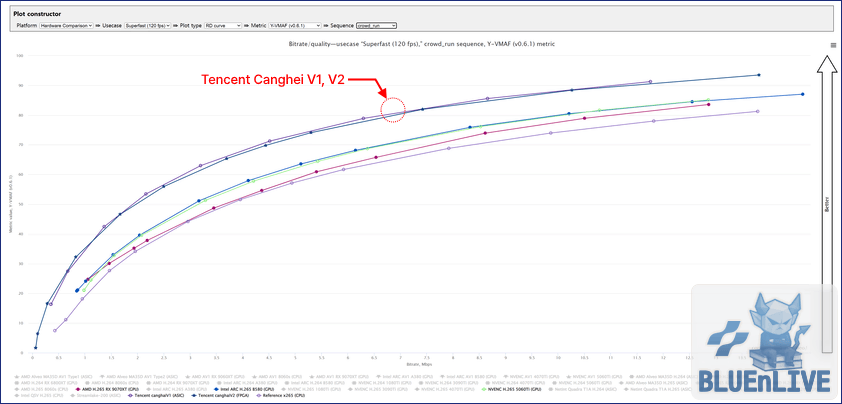 최신 GPU 3사의 HEVC vs Tencent ASIC / x265
최신 GPU 3사의 HEVC vs Tencent ASIC / x265
H.264 시절보다 GPU 곡선이 눈에 띄게 위로 올라왔다.
x265 S/W보다 나은 결과를 보이는 것을 보면 상용 GPU 미디어 엔진의 성숙도가 높아졌다는 걸 알 수 있다.
범용적인 주류 코덱으로서 준수한 효율을 증명한다.
6. 차세대의 도약: AV1
라이선스 프리와 고효율을 무기로 빠르게 영역을 넓히고 있는 차세대 코덱 AV1이다.
하지만 하드웨어 인코더 시장 전체를 보면 기대만큼의 일제히 일어난 도약은 없다.
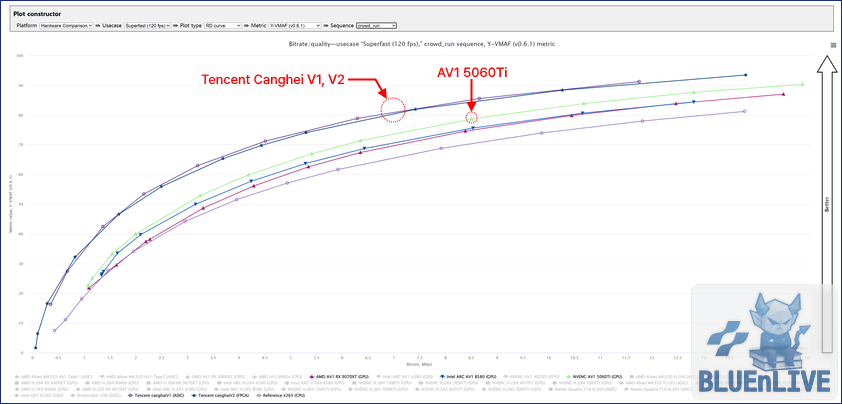 최신 GPU 3사의 AV1 vs Tencent ASIC / x265
최신 GPU 3사의 AV1 vs Tencent ASIC / x265
지표를 뜯어보면 냉정한 현실이 보인다.
NVIDIA의 최신 세대(Blackwell 아키텍처) AV1 인코더는 전 세대 대비 눈에 띄는 화질 성장을 이루어냈다.
반면 타 제조사(Intel, AMD)의 제품들은 자사의 HEVC 결과와 비교했을 때 비슷한 효율에 머물러 있다.
코덱 규격이 AV1으로 바뀌었다고 해서 모든 GPU가 드라마틱한 품질 향상을 보여주는 것은 아님을 뜻한다.
인텔 쪽은 H.264 시절 QSV의 품질과 비교해보면 뭔가 많이 아쉽고 안타깝기까지 하다.
그래도 고무적인 점은, 세 제조사의 AV1 인코더 모두 x265 S/W보다는 조금이나마 위쪽에 위치하고 있다는 사실이다.
상용 GPU들 역시 차세대 코덱다운 화질적 이점을 기본적으로 챙기고 있음을 알 수 있다.
7. 본질의 확인: “규격보다는 구현이다”
최신 GPU 3사의 HEVC와 AV1을 동시에 켜고, Canghai ASIC과 대조하면 가장 흥미로운 본질이 드러난다.
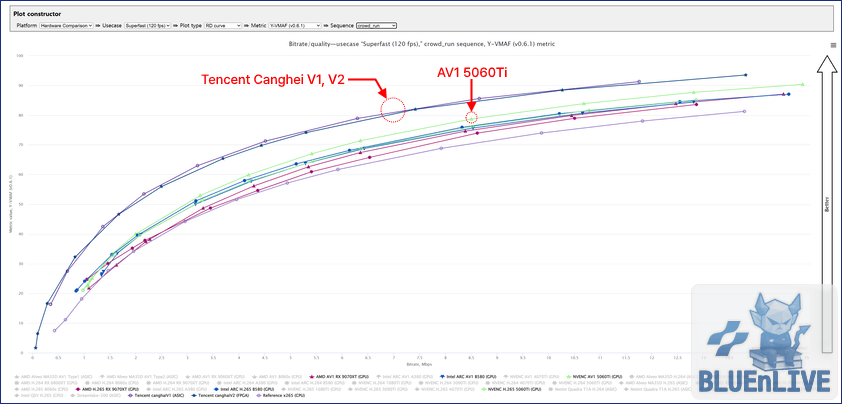 최신 GPU 3사의 HEVC 및 AV1 vs Tencent ASIC / x265
최신 GPU 3사의 HEVC 및 AV1 vs Tencent ASIC / x265
상용 GPU의 AV1 인코더들은 x265 기준점을 넘어서며 훌륭하게 제 몫을 해주고 있긴 하다.
하지만, 극상으로 튜닝된 Tencent Canghai HEVC ASIC은 최신 GPU들의 AV1보다 확연히 앞선 곡선을 보여준다.
규격상으로는 분명 AV1이 HEVC보다 진보한 코덱이다.
하지만 칩 제조사가 한정된 실리콘 면적과 전력 한계 내에서 범용성을 고려하며 하드웨어를 구현할 때와, 오직 압축 효율 하나에 모든 자원을 올인해 전용 칩(ASIC)을 설계할 때의 체급 차이가 여기에서 나타난다.
결국 비디오 압축 세계에서는 규격(Standard)의 이름표보다 구현(Implementation)의 완성도가 우선한다는 것이다.
8. 현실적인 타협점: Speed / Quality의 방정식
물론 우리는 서버룸이 아닌 개인의 PC 환경에서 작업을 수행한다.
화질이 극강이라는 이유로 개인이 클라우드 독점 ASIC을 가져다 쓰는 건 거의 불가능하다.
여기서 인코딩 속도와 화질의 밸런스를 보는 Speed/Quality 그래프로 시선을 돌려본다.
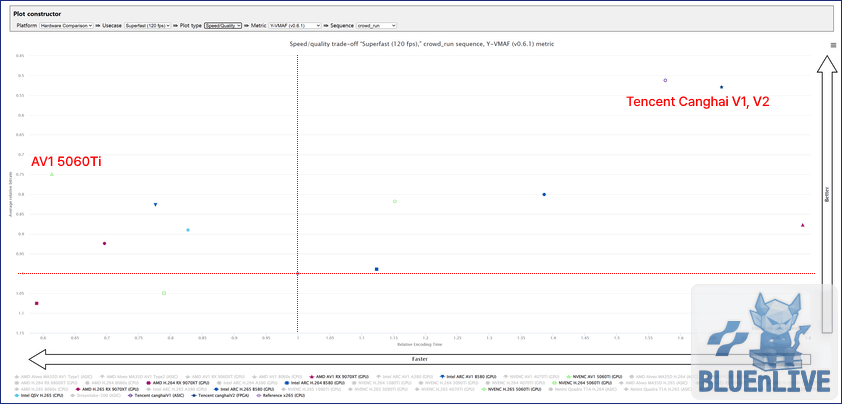 Speed/Quality 환경에서의 최신 GPU 3사 코덱별 비교 vs Tencent / x265
Speed/Quality 환경에서의 최신 GPU 3사 코덱별 비교 vs Tencent / x265
전용 ASIC 장비들이 압축률을 짜내기 위해 시간을 소모할 때, 상용 GPU들은 압도적인 처리량을 선보인다.
특히 RTX 5070 Ti 등에 탑재된 최신 Blackwell 아키텍처의 9세대 NVENC AV1 인코더는 훌륭한 균형점이다.
듀얼 인코더 하드웨어 구조를 통해 인코딩 속도를 극상으로 끌어올렸다.
무엇보다 에코시스템의 차이가 절대적이다.
클라우드 ASIC은 구매하기도 쉽지 않다.
게다가, 전용 SDK나 커스텀 빌드된 FFmpeg을 통해 CLI 환경에서 어렵게 제어해야 한다.
반면 상용 GPU의 AV1은 프리미어, 다빈치 디졸브 등 보통 사용되는 모든 미디어 프레임워크와 네이티브로 연동된다.
코드 몇 줄로 이 막강한 하드웨어 피지컬을 끌어다 쓸 수 있다는 점은 전용 칩이 따라올 수 없는 무기다.
맺으며
2025 MSU 하드웨어 레포트는 코덱의 세대론적 환상을 깨뜨렸다.
하드웨어 아키텍처와 실리콘 투자가 만드는 피지컬의 차이를 명확하게 보여준 지표다.
비용 절감을 위해 구세대 규격을 극한까지 고도화한 빅테크의 집념도 놀랍고, 제한된 실리콘 안에서 대중성과 속도, 품질의 최적 균형을 찾아낸 상용 GPU 미디어 엔진의 성숙함 역시 깊은 인상을 남긴다.
결국 최고의 시스템은 절대적인 수치 위의 장비가 아니다.
내 작업 파이프라인의 목적과 생태계에 부합하는 장비가 곧 정답일 것이다.
